14.07.2023
Author: Khoa Nguyen
End users need our recommendations!
Nowadays, it's almost impossible to think of any platforms that don't use recommendations. We more or less take it for granted that we will be given product recommendations in an online shop or friendship suggestions on a social network. In this blog post, we will show how we are developing a recommender system and we will also share our findings.
Building a recommender system used to require a great deal of specialist knowledge and often an elaborate technical setup as well. In the last few years, however, the software platform world has changed and developed in the direction of "as-a-service" solutions. Complete solutions are offered as a ready-to-use service, where previously a complex procedure involving setup and configuration had been essential. This is interesting because new services can be tested quickly without a lot of time, effort and expense.
We have been testing two different approaches to Recommender Systems.
Today, there are also various as-a-service solutions in the field of recommender systems. This is why we decided to implement a classic recommender solution for friendship suggestions on social networks. We chose two different approaches to do this:
- A graphical approach with the service product AWS Neptun
- A machine-learning approach with the service product AWS Personalize
This blog goes into more detail about both approaches and also explains what we have learnt.

1st approach:
Graph dependency
A common approach to getting friend suggestions is the friend-of-friend approach. This approach works on the assumption that if two people have many of the same friends, there is a high probability that they will also become friends, or they may even know each other.
Friendship relationships like these are ideal pieces of data that can be mapped as graph dependencies. The reason for this is that a graph consists of nodes and edges. A node represents an entity such as a person and edges show the relationships between the nodes.
In the practical example with a social network, this produces the following specific example: Now if we want find people who are friends with Max (red node), then we will run the following search: Find the node with the name Max. From this node, give me all the nodes that are connected by an edge (blue nodes).
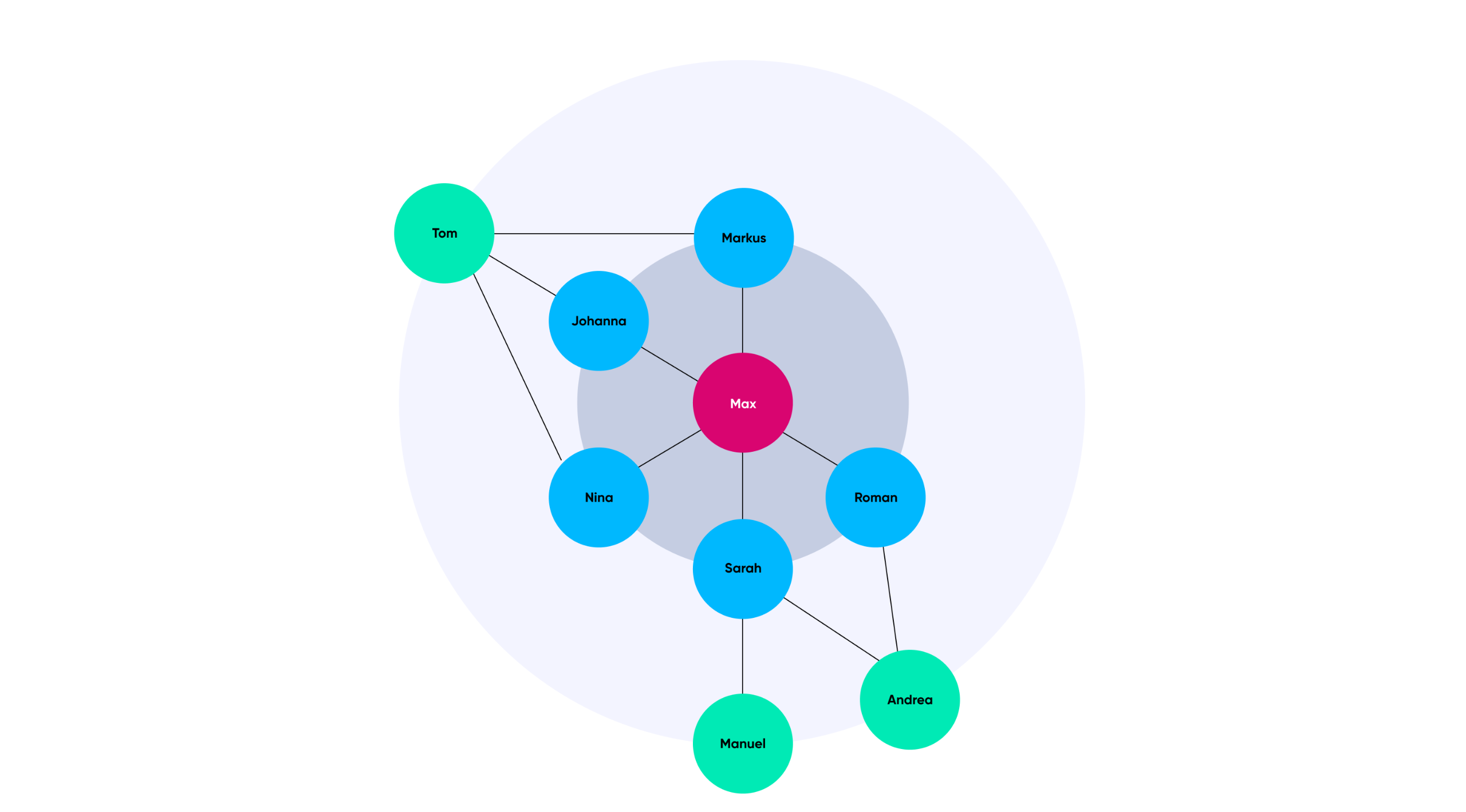.png)
The friend-of-friend approach produces the most likely results.
Now we want to find everyone who is a friend of one of Max's friends (green nodes). If we do this, we get what is known as a graph traversal, the same people may even be included several times in the results we get, as some of the nodes are connected by several edges. This is practical because it basically gives us a weighting of how many identical friends the people in the second set of results have. According to the friend-of-friend approach, the likelihood that two people could be friends is highest if they already have a lot of friends in common. This last search therefore returns the list of recommended people with the corresponding weighting (Tom - 3, Andrea - 2, Manuel -1).

2nd approach:
Machine Learning
There are plenty of machine-learning algorithms that are better for certain problems than others. An important part of machine learning is cleaning up and preparing the data. Typically, this involves the cleaning of statistical outliers in the data or the detection of anomalies in that dataset, which may be triggered by issues like errors in taking measurements.
We didn't want to start from scratch with machine learning, but wanted to use a ready-made service from AWS so that we could use machine learning as-a-service without too much trouble. To do this, we used AWS Personalize, which promises that it can use machine learning to generate curated recommendations quickly. AWS Personalize automatically analyses the data it has been given and trains a recommendation model. The recommendations can then be conveniently interrogated using its own interface.
How does AWS Personalize build its recommendation model?
We entered the same social network data as in the graph approach and started to extract recommendations for friends. However, we ended up with some strange results. The set of results is not bad per se, but we still wouldn't say it was a good recommendation. So, we took a closer look at how AWS Personalize builds its recommendation model and eventually we were able to work out what was happening.
AWS Personalize was built with the aim of providing users with a simple platform to create recommendations for films or online shop products. With this in mind, AWS Personalize places some emphasis on making a recommendation, such as recommending popular items. This allows it to create recommendations that generate hype in customers, such as for a new series of films or a new trending product.
If we now enter friendship data, AWS Personalize may interpret a person with a large number of friends as something popular and recommend them to everyone else, even though there is no relationship between these people. In addition, AWS Personalize also takes the time aspect into account. This means that older interaction data is weighted less heavily than current interactions. This makes sense for film recommendations but is less useful for recommended friendships. However, AWS Personalize also takes the grouping of similar things into account if they seem to interact together more often. This latter feature now produces the intended result, so that similar groups of people are recommended to each other.
Questions on the topic «Recommender System»?
Contact Khoa:

What have we learnt?
Today the rapidly growing world of as-a-service products allows us to access a range of technologies and services that previously could only be set up with a lot of initial effort and knowledge. We were able to test two different approaches for friend recommendations in a very short period of time and quickly develop a proof-of-concept. We saw that the graph approach can help us enormously when the data has relationships. Graph databases like AWS Neptune are optimised to query and traverse graph-mapped data efficiently. We also learnt that while AWS Personalize is very easy to use, if the dataset is not suitable, the well-known American expression "garbage in - garbage out" still applies.