14.07.2023
Autor: Khoa Nguyen
Endnutzer:innen brauchen unsere Empfehlungen!
Plattformen ohne Empfehlungen sind heute kaum noch denkbar. Es ist fast selbstverständlich, dass man in einem Onlineshop Produktempfehlungen erhält oder auf einem sozialen Netzwerk Vorschläge für Freundschaften bekommt. Im diesem Blogpost zeigen wir auf, wie wir ein Empfehlungssystem entwickeln und teilen unsere Erkenntnisse.
Ein Empfehlungssystem zu bauen, bedingte früher fundiertes Fachwissen und häufig ein aufwendiges technisches Setup. In den letzten Jahren hat sich die Softwareplattformwelt aber verändert und entwickelt sich in Richtung «as-a-Service» Dienstleistungen. So werden komplette Lösungen fertig als eine einfach zu beziehende Dienstleistung angeboten, wo früher ein aufwendiges Setup und Konfiguration benötigt wurde. Dies ist interessant, da ohne hohe Aufwände neue Services rasch getestet werden können.
Wir haben zwei Recommender System Ansätze getestet.
Auch im Bereich von Recommender Systemen gibt es heute diverse as-a-Service Lösungen. Wir haben uns deshalb vorgenommen, eine klassische Recommenderlösung für Vorschläge von Freundschaften auf sozialen Netzwerken umzusetzen. Hierfür haben wir zwei verschiedene Ansätze gewählt:
- Graphansatz mit dem Service Produkt AWS Neptun
- Machine Learning Ansatz mit dem Service Produkt AWS Personalize
In diesem Blog wird auf beide Ansätze näher eingegangen und unsere Ergebnisse erklärt.

1. Ansatz:
Graphenabhängigkeit
Ein häufiger Ansatz um Vorschläge für Freunde zu erhalten, ist der Friend-of-Friend Ansatz. Dieser Ansatz geht davon aus, dass wenn zwei Personen viele gleiche Freunde haben, die Wahrscheinlichkeit gross ist, dass sie auch Freunde werden bzw. sich kennen.
Solche Freundschaftsbeziehungen sind ideale Daten, um sie als Graphenabhängigkeit abzubilden. Denn ein Graph besteht aus Knoten und Kanten. Ein Knoten stellt eine Entität wie z.B. eine Person dar und Kanten zeigen die Beziehungen zwischen den Knoten auf.
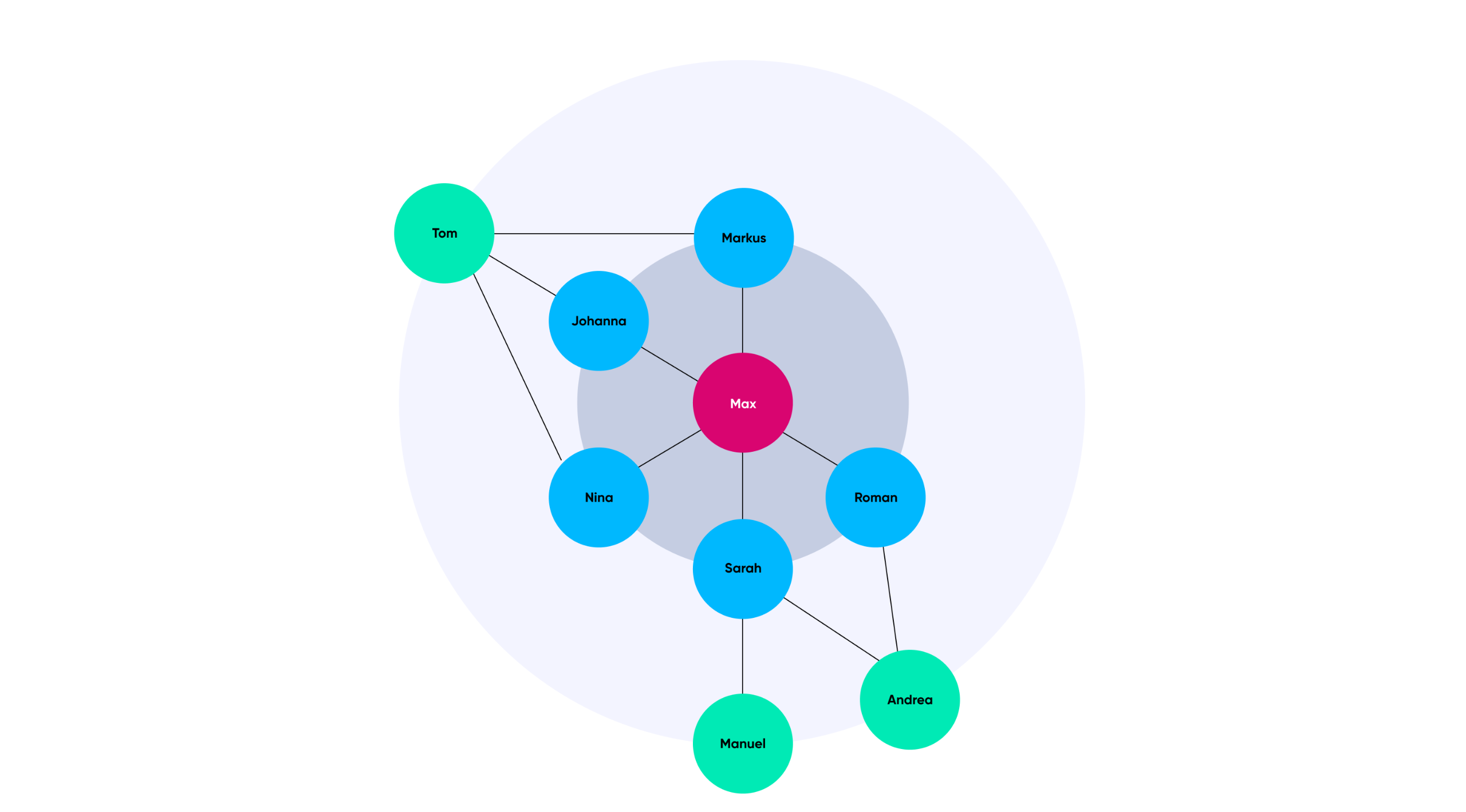
Im Praxis Beispiel mit einem Sozialnetzwerk ergibt dies das folgende konkrete Beispiel: Wenn wir nun die Freunde von Max (roter Knoten) erhalten möchten, dann werden wir eine Abfrage wie folgt durchführen: Finde den Knoten mit dem Namen Max. Von diesem Knoten gib mir alle Knoten, die über eine Kante verbunden sind (blaue Knoten).
.png)
Höchste Wahrscheinlichkeit mit dem Friend-of-Friend Ansatz.
Nun möchten wir alle Freunde von den Freunden von Max erhalten (grüne Knoten). Bei dieser sogenannten Graphtraversierung werden auch gleiche Personen mehrfach im Resultatset enthalten sein, da die Knoten zum Teil mit mehreren Kanten verbunden sind. Dies ist praktisch, denn es gibt uns quasi eine Gewichtung, wie viele gleiche Freunde die Personen im zweiten Resultatset haben. Nach dem Friend-of-Friend Ansatz ist die Wahrscheinlichkeit am höchsten, dass zwei Personen befreundet sein könnten, wenn sie bereits viele gemeinsame Freunde haben. Diese letzte Abfrage gibt somit die gesuchte Liste mit den zu empfehlenden Personen zurück mit der entsprechenden Gewichtung (Tom - 3, Andrea - 2, Manuel -1).

2. Ansatz:
Machine Learning
Es gibt viele Machine Learning Algorithmen, welche für gewisse Probleme besser oder weniger gut geeignet sind. Ein wichtiger Bestandteil im Machine Learning ist die Bereinigung und Aufbereitung der Daten. Typische Schritte sind die Bereinigung von statistischen Ausreissern in den Daten oder die Erkennung von Anomalien in den Daten, z.B. ausgelöst durch Messfehler.
Wir wollten uns nicht von Grund auf mit Machine Learning auseinandersetzen, sondern einen fertigen Service von AWS einsetzen, damit wir ohne hohen Aufwand Machine Learning as-a-Service benutzen können. Hierfür haben wir AWS Personalize eingesetzt, das verspricht, mittels Machine Learning schnell kuratierte Empfehlungen erzeugen zu können. Dabei analysiert AWS Personalize automatisch die bereitgestellten Daten und trainiert ein Empfehlungsmodell. Über eine Schnittstelle können anschliessend die Empfehlungen bequem abgefragt werden.
Wie baut AWS Personalize sein Empfehlungsmodell?
Wir haben die gleichen sozialen Netzwerkdaten wie beim Graphansatz eingepflegt und begonnen, Empfehlungen für Freunde herauszuladen. Dabei kamen wir aber zu einem merkwürdigen Resultat. Das Resultatset ist per se nicht schlecht, aber wir würden es trotzdem nicht als eine gute Empfehlung interpretieren. Wir haben uns deshalb vertieft damit auseinandergesetzt, wie AWS Personalize sein Empfehlungsmodell baut und konnten mit der Zeit nachvollziehen, was geschehen war.
AWS Personalize wurde mit dem Ziel gebaut, Nutzer:innen eine einfache Plattform zu bieten, Empfehlungen für Filme oder Online Shop Produkte zu erstellen. Für diesen Anwendungszweck hat AWS Personalize einige Schwerpunkte in der Empfehlung gesetzt, wie die Empfehlung für populäre Dinge. Dies ermöglicht es, einen Hype an Kunden zu empfehlen, wie z.B. eine neue Filmserie oder ein neues Trendprodukt.
Wenn wir nun Freundschaftsdaten einpflegen, dann interpretiert AWS Personalize möglicherweise eine Person mit sehr vielen Freunden als ein populäres Ding und empfiehlt dies allen anderen Personen, obwohl keine Beziehung zwischen den Personen besteht. Weiter berücksichtigt AWS Personalize auch den zeitlichen Aspekt. Das heisst, ältere Interaktionsdaten werden weniger stark gewichtet als aktuelle Interaktionen. Dies macht für Filmempfehlungen durchaus Sinn, ist aber für Freundschaftsempfehlungen weniger sinnvoll. AWS Personalize berücksichtigt aber auch die Gruppierung von ähnlichen Dingen, die scheinbar öfters zusammen interagieren. Diese letztere Eigenschaft führt nun zum gewünschten Resultat, so dass ähnliche Personengruppen gegenseitig empfohlen werden.
Fragen zum Thema «Recommender System»?
Kontaktiere Khoa:

Was haben wir gelernt?
Die heutige rasant wachsende as-a-Service Welt ermöglicht den Zugang zu verschiedenen Technologien und Services, welche früher nur mit viel Initialaufwand und Wissen aufgesetzt werden konnten. Wir konnten so in kürzester Zeit zwei verschiedene Ansätze für Friends Recommendation implementieren und schnell einen Proof-of-Concept entwicklen. Wir haben gesehen, dass uns der Graphansatz enorm helfen kann, wenn die Daten Beziehungen aufweisen. Graphdatenbanken wie AWS Neptun sind dazu optimiert, als Graph abgebildete Daten, effizient zu abzufragen respektive zu traveriseren. Weiter haben wir gelernt, dass AWS Personalize zwar sehr einfach zu benutzen ist, mit ungeeigneten Daten jedoch nach wie vor der bekannte Spruch «garbage in – garbage out» gilt.